MyAnimeList recommender: Web Scraping
Once upon a time (actually quite recently), I got a membership for Crunchyroll, the "Netflix but way worse than actual Netflix" of anime, right in the middle of exam season as reasonable students do. After a couple shows, I was left staring at a void, not knowing what show I should watch next while keeping in mind that studying was not an option at the time. I've realized I've been spoiled by Netflix and Youtube's content recommender, so I decided that Crunchyroll needs one. This blog post is a first step in building a recommender system.
Since this is my first time scraping the web, I figured it would be helpful to outline the steps I did, from a fresh beginner's perspective, to help out anybody reading.
Finding the data
Before we can scrape the site, we first need to know where exactly the data is. How would a human find this data? As it turns out, MyAnimeList has a users page. They won't give us a huge list of every user, somewhat unfortunately, so we'll make do with the 20 online users that it presents us.
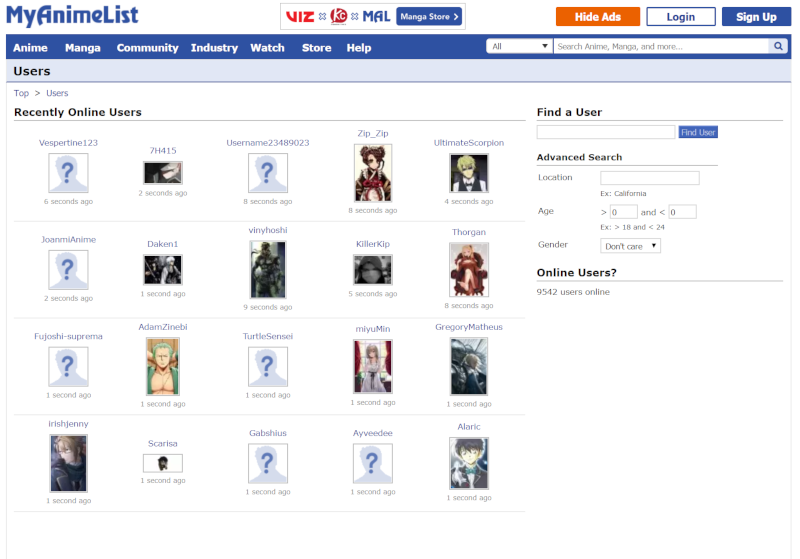
Although we don't have the complete list of users, we do know that whatever users we scrape from here, they've been online recently, so at least we know we don't have inactive users.
How do we go through each of these users?
It turns out that the picSurround class gives us exactly the 20 users we're looking for. Although we are looking for the a tag that gives the profile link itself, that tag is not as specific as picSurround, despite it being 'deeper' in the HTML hierarchy. There are likely a multitude of different ways to approach this, as long as you get the profile URLs.
>>> from bs4 import BeautifulSoup
>>> import requests
>>> response = requests.get("https://myanimelist.net/users.php")
>>> soup = BeautifulSoup(response.text, 'html.parser')
>>> recentOnlineUsers = soup.find_all(class_='picSurround')
>>> len(recentOnlineUsers)
20
>>> recentOnlineUsers[0]
<div class="picSurround"><a href="/profile/Ioane-_-"><img border="0" src="https://cdn.myanimelist.net/images/questionmark_50.gif"/></a></div>
>>> recentOnlineUsers[0].find('a').get('href')
'/profile/Ioane-_-'
Visiting a user's page (I'm not going to bother omitting any details about the particular user, because their page is public), I figure that the mean score and days watched were good indicators of their bias and 'experience', respectively. We can grab these by using the inspector tool.
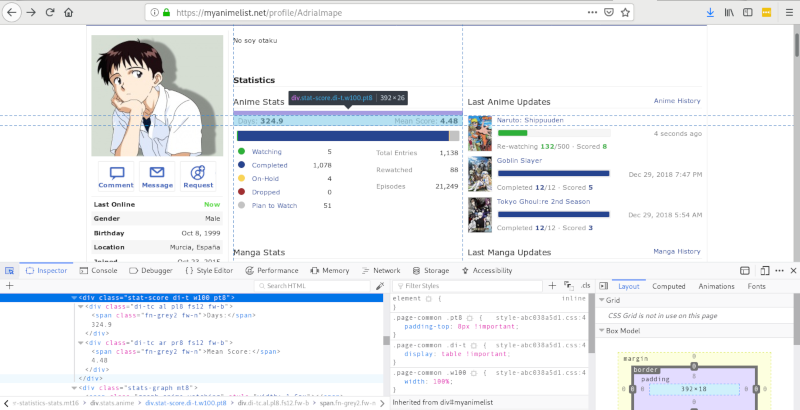
profileResp = requests.get("https://myanimelist.net" + profile)
profileSoup = BeautifulSoup(profileResp.text, 'html.parser')
statsAnime = profileSoup.find(class_ = "stats anime")
if statsAnime:
statScore = statsAnime.find(class_="stat-score")
statScore = [x for x in list(statScore.children) if x != '\n'] # get two subdivs, without newlines
statScore[0].find('span').text
numdays = int(float(statScore[0].text.split(': ')[1])) # ['Days', '213.4']
meanscore = int(float(statScore[1].text.split(': ')[1])) # ['Mea Score', '6.92']
else:
numdays=-1
meanscore=-1
Now, the meat of it all, what animes did they watch? Thankfully, it's as simple as visiting animelistURL = 'https://myanimelist.net/animelist/' + username
But wait! A catch! Look and see what happens when you scroll through the anime list page of a true weeb (read: find an anime profile with more than 300 anime in their list)
The full list of anime isn't presented to us at first. It seems to be getting more information as we scroll, so there is some dynamic aspect at play here. One trick to keep in mind is that they might try to hit a URL on the server that processes the requests, and sends back the information. Luckily for us, it is fairly straightforward. Open up your friendly neighbourhood developer console and go to the network tab, make sure "XHR" is selected. Now scroll down and once you hit the bottom, you should see a request being made.
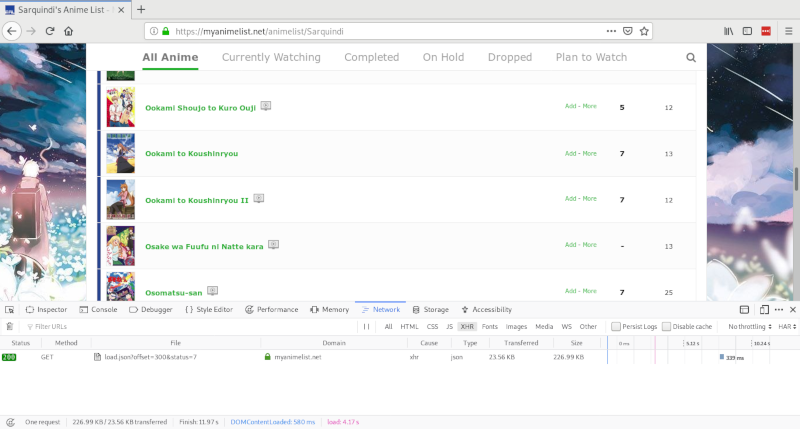
Now that we have this URL, what does it actually look like if we try to call it ourselves? Lets take this URL and put it into our browser

It looks crazy, but it's actually JSON (same thing?). If you're unfamiliar, it's a data structure that represents a object with many different properties. In this case, it would represent an anime, and some of its properties might be its name, genre, studio, etc. It looks messy now because the whitespace isn't optimal for reading, but this can easily be parsed in Python:
import json
listRequest = requests.get("https://myanimelist.net/animelist/Adrialmape/load.json?offset=300&status=7")
animelistJSON = json.loads(listRequest)
animelistJSON[0]["anime_id"] # 376
animelistJSON[0]["anime_title"] # 'Elfen ........ '
Now what we have to do is keep increasing the offset parameter in that URL until it returns nothing.
animelistURL = 'https://myanimelist.net/animelist/' + username
currPage = 0
# there is a chance that the server acts up. Hopefully, it doesn't. If it does, catch the exception.
try:
while True:
print("Currpage: " + str(currPage))
listRequest = expo_request(animelistURL + '/load.json?offset=' + str(currPage*300) + '&status=7' , max_retries=7,debug=True)
animelist = json.loads(listRequest.text)
if animelist == [] or not listRequest.ok:
break
runninglist += animelist
currPage += 1
time.sleep(2)
except (ValueError, RetryException) as e:
print(e)
Here I am using a custom function expo_request that piggybacks off the requests package. It requests a URL and if it fails, waits some time before retrying. If it fails again, wait even longer. The increase in waiting time is exponential. The server is not happy about so many requests, and will try to rate-limit. I have tried to limit the requests to once every two seconds, but sometimes a longer wait is needed.
Now we have all the anime! All that's left is to package up all the steps we did here for one user, and loop the crap out of it until you've got all the data you need. Happy scraping!